

A Ciência de Dados é um campo que já existe há algum tempo, porém ganhou mais destaque nos últimos anos devido a popularização da Big Data, o amadurecimento de áreas como o Machine Learning (aprendizado de máquina) e a evolução da capacidade de processamento computacional.
A Data Science é capaz de transformar uma quantidade (grande ou pequena) de dados brutos em insights de negócios, sempre com o objetivo de auxiliar as empresas na tomada de decisões estratégicas e alcançar melhores resultados. Ela faz isso por meio de métodos estatísticos e algoritmos que tentam encontrar padrões nos dados para descrevê-los ou fazer predições do que acontecerá no futuro através de modelos preditivos.
A resposta é simples: é uma função matemática que, aplicada a uma massa de dados, consegue identificar regras ocultas e prever o que poderá ocorrer.
Um bom exemplo de problema de negócio que utiliza Ciência de Dados é a análise de crédito utilizada pelos bancos e financeiras ao conceder empréstimos. Eles entendem os dados históricos dos clientes que solicitaram crédito, e através de modelos preditivos, conseguem identificar padrões comportamentais para prever quem serão os bons pagadores ou inadimplentes no futuro.
Existem dois tipos de modelos preditivos, os supervisionados e os não supervisionados. No supervisionado, em que daremos foco neste post, os dados necessários para fazer o modelo aprender e a variável "Alvo" (aquilo que se deseja prever) são estudados em conjunto nos dados.
Ou seja, a base para treinamento é rotulada com o que já aconteceu no passado, informando alguns exemplos de casos daquilo que se deseja prever. Isso serve para que o modelo aprenda e encontre correlações entre as variáveis (atributos de cada cliente) com o "Alvo". Geralmente em problemas de negócios, utilizamos os modelos preditivos supervisionados e com bases de centenas de milhares ou milhões de registros.
Veja um exemplo hipotético de layout de base utilizada para treinamento de um modelo de concessão de crédito:
Abaixo, é possível visualizar um exemplo de fluxo simplificado de como um modelo preditivo é criado para o problema de inadimplência em bancos e financeiras utilizando esse layout. O objetivo neste exemplo, é fazer o modelo prever se clientes desconhecidos serão bons pagadores ou inadimplentes no futuro.
Observe que, a partir dos dados históricos de cada cliente, aplicamos algoritmos de machine learning para achar correlações entre os seus atributos e a variável "Alvo" e tentar encontrar padrões que fazem um cliente ser um bom ou mau pagador.
O resultado do processo é um modelo treinado capaz de identificar novos clientes que não estavam nos dados iniciais e classificá-los se são bons pagadores ou inadimplentes atráves de um "Score" (pontuação). No exemplo acima, esse Score representa que o novo cliente desconhecido, em uma escala de 0 a 100, alcançou a pontuação 92 de ser um bom pagador. Ou seja, a "chance" de ele pagar o empréstimo é muito grande.
Dessa forma, ao colocar um modelo preditivo em produção, é possível ajudar os bancos e financeiras a decidirem de forma mais precisa se vale a pena conceder empréstimo para um determinado cliente ou se ele representa um grande risco de não pagar a dívida.
Agora que sabemos o que é um modelo preditivo,
qual o processo utilizado para resolver problemas de negócios?
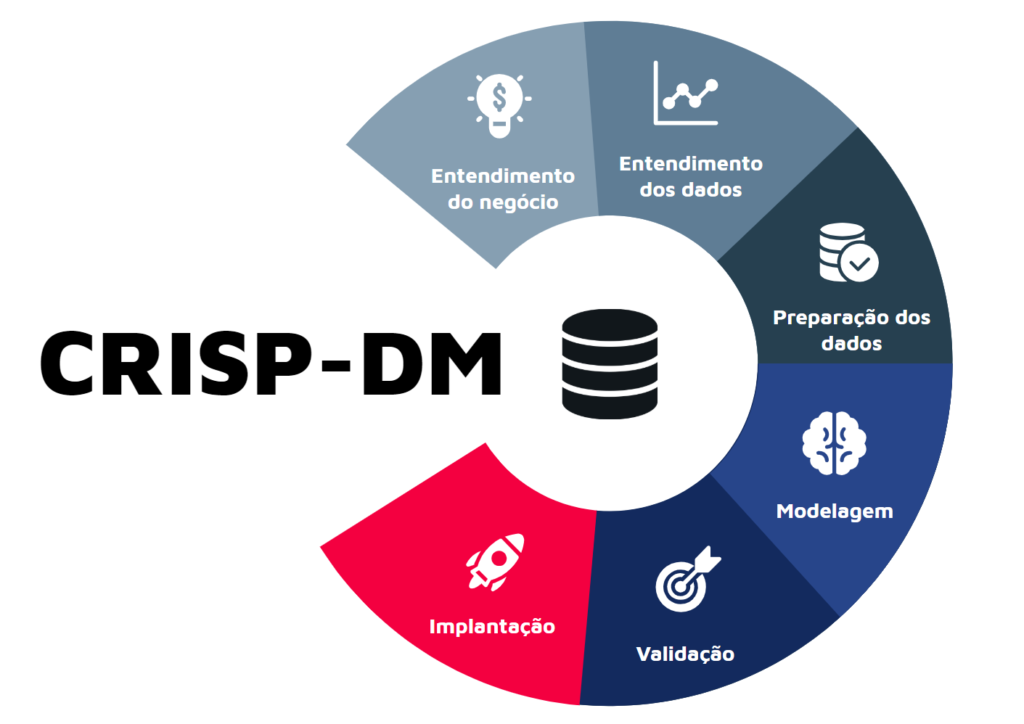
Na Neurotech, utilizamos um dos principais frameworks para resolução de problemas de negócios com dados, o CRISP-DM (Cross-industry Process for Data Mining). É uma metodologia amplamente usada em Ciência de Dados para ajudar empresas na tomada de decisões estratégicas pela sua facilidade e aplicabilidade.
Ele é dividido em 6 etapas. Observe que criar um modelo é apenas uma das fases desse processo:
O melhor modelo que existe é aquele que está em produção. Não existe um modelo que acerte 100% dos casos, se isto estiver acontecendo, algum erro pode estar pertubando os seus dados e causando overfitting (sobreajuste). Por outro lado, um modelo que acerta bem mas não é colocado em produção com clientes reais, não possui valor de negócio.
Ou seja, para que um modelo preditivo realmente ajude na tomada de decisões nas empresas, é preciso colocá-lo à prova e geralmente fazemos isso através de uma Análise de Impacto Financeiro, mas isso é tema para um outro post.
E você, como utiliza a Data Science nos seus negócios?


