

Por: *Rodrigo Cunha | 25 de Setembro de 2018
Encontrar cientistas de dados não é uma missão fácil. Mas depois que eles são achados, temos outro desafio: fazer com que esses profissionais entendam as dores do mercado, ou seja, entendam o negócio do cliente. Na maioria das vezes, o cientista de dados fica só na formação acadêmica, sem entender do mercado, e sai com modelos completamente irreais, que não resolvem o que precisam resolver! Não dá, pessoal! Empresas que empregam cientistas de dados têm clientes e eles precisam ser compreendidos, senão não tem como entregar os resultados esperados.
Para ser bem direto, os cientistas de dados têm que ter contato direto com o cliente. Em vez de ficar só “dentro de casa” fazendo os modelos, eles precisam participar de todas as reuniões de entendimento do problema: reunião de levantamento de expectativas, reunião de levantamento dos dados… É isso que vai transformar a forma como eles vão visualizar os dados. Essa postura favorece, inclusive, o formato de trabalho em squads (pequenos grupos multidisciplinares autônomos), que funciona muito bem na Neurotech, entendendo o cliente independente da área em que ele atua.
É tanto que vemos, claramente, como os colaboradores que interagem com o cliente se desenvolvem em uma velocidade de 3, 4, 5 vezes maior em relação aos que ficam trancados com seus dados e algoritmos.
É claro que, quando olhamos sob a perspectiva de formação de time, sabemos que nós, profissionais sêniores e gestores, somos quem precisa abrir os olhos da garotada. Até porque é muito comum termos cientistas de dados com nível de conhecimento muito inicial, recém-saídos da faculdade (ainda não há uma massa crítica disponível em nível sênior). Só que, em pouquíssimo tempo, esse tipo de atitude, ou pelo menos essa iniciativa, vai virar um pré-requisito. Fiquem atentos!

Vamos a um exemplo real: imagine que uma empresa tem que conceder crédito para clientes que querem financiar veículos. Considere que, na análise desse crédito, existe uma variável: o comprometimento da renda da pessoa física que pede o financiamento, ou seja, o quanto essa dívida vai representar em cima do que essa pessoa tem de receita. No mercado, existe a máxima de que, quanto maior esse comprometimento, maior a chance de inadimplência e, por isso, há uma convenção de que o limite é de 30%.
Ou seja, se o consumidor está com 30% dos seus rendimentos presos a dívidas a serem pagas, é muito alto o risco de ele não honrar novas dívidas. Apesar de o cenário descrito no parágrafo anterior ser até comum e conhecido por muita gente, no nosso exemplo teve uma virada. Descobrimos que entre aqueles compradores que, por algum motivo, extrapolavam esse limite – comprometiam 40% da renda, por exemplo –, o índice de inadimplência caía muito. Qual a lógica disso, se até 30% o risco só aumentava?
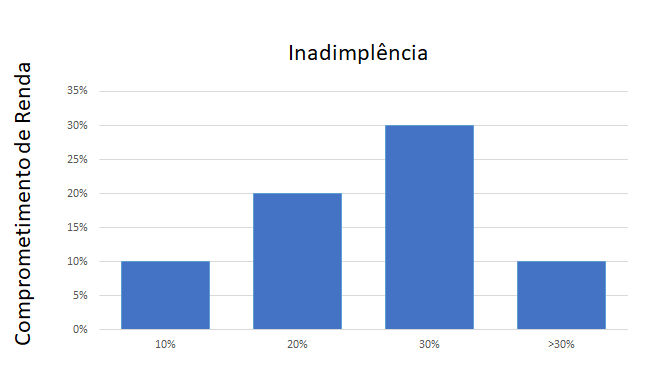
O “segredo” só pôde ser descoberto com um olhar atento ao cliente. Ao conversar com ele, ouvir seus relatos e entender os bastidores do dia a dia da concessão de crédito, entendemos que 30% era uma regra da empresa aplicada de modo geral. Porém havia exceções. Quem estava acima desse limite e tinha algum relacionamento com alguém dentro da empresa conseguia ser aprovado com a indicação (com o aval) desse funcionário e, consequentemente, obtinha o financiamento.
Para um cientista de dados sem a compreensão do que acontecia com o cliente, que pegasse somente o banco de dados, poderia ser um caso simples de uma variável não linear, ou seja, que se comporta de forma inconstante sem padrões aparentes. E, assim, ele faria um modelo completamente errado. Resultado: havia uma variável importantíssima fora do banco de dados, que era o relacionamento do requerente com funcionários da empresa; uma espécie de acordo tácito que não tinha como ser “descoberto” numa visão apenas em cima dos dados frios. Então, na verdade, era uma variável linear, o que muda completamente a forma como o modelo é construído.
Esse tipo de preocupação, de não só olhar os dados, mas enxergar o negócio em si e que tipo de problema estamos tentando resolver, é fundamental para podermos alcançar os resultados esperados. Assim, há um impacto direto numa métrica importantíssima para qualquer negócio que quer ser relevante para o cliente: o Lifetime Value (LTV). O LTV indica o valor do cliente no ciclo de vida, o quanto ele investe durante o relacionamento com sua empresa.
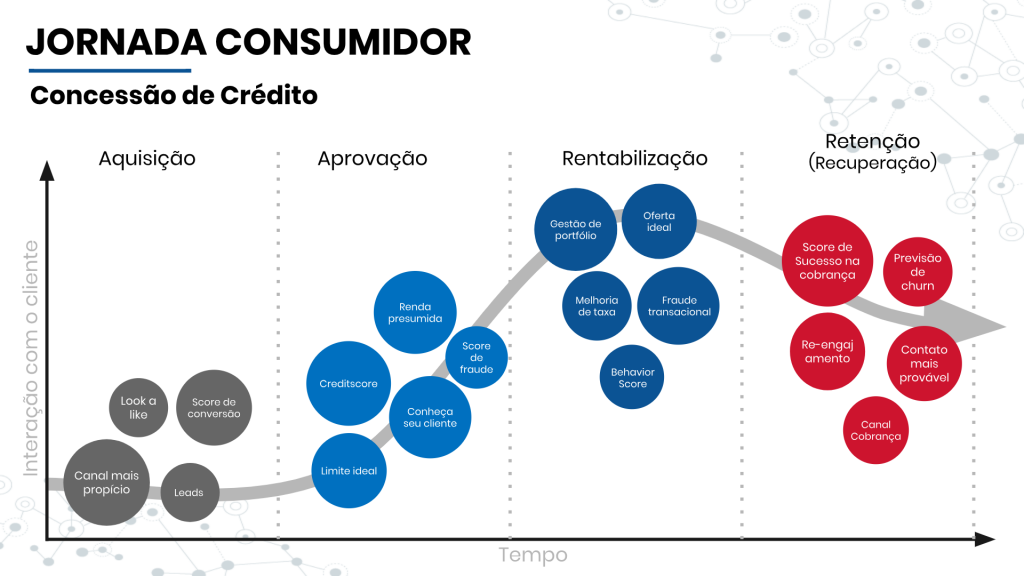
Mas o que tudo isso quer dizer? Quer dizer que o foco é atingir os objetivos do cliente, resolvendo o problema dele em cada etapa do LTV, em vez de ficar escovando bit dentro de uma caverna. Acho que já deu para perceber que entender as dores do cliente e, de um modo geral, do mercado está entre as maiores preocupações da Neurotech em 2019, não é?
Os benefícios que vamos gerar só podem vir de um entendimento e de um aprofundamento dos detalhes do negócio. Veja que nosso propósito é “Conectar dados com inteligência por um futuro mais previsível”: essa inteligência não está no machine learning, que é nossa ferramenta, está na estratégia usada para resolver problemas e gerar resultados de impacto.
E você? Está mais preocupado em entender seu cliente ou em ficar isolado com seus dados?
*Rodrigo Cunha | Director of Machine Learning and Big Data at Neurotech


