

Nos últimos anos, estamos presenciando um rápido crescimento e popularização da ciência de dados ao redor do mundo. Na Neurotech, desenvolvemos soluções avançadas de inteligência artificial e analíticas há quase 20 anos e, entre erros e acertos, adquirimos bastante experiência sobre o tema.
Fazer ciência de dados envolve o desenvolvimento de uma solução dividida em etapas centradas na informação e na tomada de decisões, possivelmente envolvendo técnicas de machine learning, estatística e outros campos do conhecimento. Em um projeto usando machine learning, após as fases de entendimento do problema, levantamento de requisitos, tratamento dos dados, modelagem e avaliação, vem uma etapa pouco mencionada nos cursos e tutoriais: a disponibilização de modelos “em produção”.
Implantar um modelo em produção significa disponibilizá-lo
em um ambiente capaz de receber solicitações
e responder de acordo com requisitos pré-estabelecidos.
Existem vários fatores a se considerar no momento de colocar um modelo em produção e um deles é o formato de disponibilização. O formato escolhido pode impactar diretamente no tempo de resposta e na disponibilidade do modelo em produção. De modo geral, podemos dividir em duas formas como um modelo pode entrar em produção: modelos fechados e modelos interoperáveis. A seguir discorremos sobre essas abordagens, suas vantagens e desvantagens e como as utilizamos ao longo da história da Neurotech.
Um modelo fechado é aquele que você treina, salva e carrega usando a mesma linguagem de programação e/ou sistema operacional.
Até a primeira década deste século, as poucas empresas que faziam uso de machine learning para resolver problemas utilizavam esse formato. A Neurotech, por exemplo, em 2006, desenvolveu uma solução com dois sistemas usando Delphi, denominados NeuroDEV e NeuroServer, que eram utilizados, respectivamente, para criar o modelo e disponibilizá-lo em produção. Os modelos construídos por essa solução eram baseados em uma rede neural com poucos neurônios divididos em duas camadas escondidas. Justamente por essa simplificação arquitetural, o tempo de resposta era baixíssimo e os modelos em produção raramente apresentavam problemas.
Com a necessidade crescente de construirmos modelos
utilizando grandes bases de dados, essa solução começou
a apresentar problemas de escalabilidade.
Nele, por exemplo, não era possível treinar
uma base com mais de 1 milhão de registros
e algumas centenas de variáveis.
Diante desse cenário e da popularização da ciência de dados, bem como o surgimento de vários frameworks de machine learning, foi preciso darmos um passo à frente. Foi nesse contexto que surgiu o Prophet, um framework desenvolvido na Neurotech com versões em Spark e python, que tem como objetivo abstrair muito dos detalhes envolvidos na criação de um modelo usando machine learning, além de facilitar a implantação do modelo em produção.Nossa primeira aposta para salvar o modelo treinado foi uma abordagem fechada usando a mesma linguagem de programação. Como uma das linguagens de programação do Prophet é python, o modo mais simples de serializar e salvar um modelo é utilizando o módulo pickle. No entanto, por ser executado em python, o tempo de execução para um modelo no formato pickle pode ser bastante elevado.
Em nossos testes, um modelo usando pickle (com etapas de tratamento de missing, outliers, codificação e predição com XGBoost) demorava um pouco mais de 1 segundo para retornar um score de um indivíduo com 200 variáveis. Na Neurotech possuímos alguns SLAs (Service Level Agreement) de tempo de resposta bem rígidos (abaixo de 200 ms) que nos impedem de usar um modelo salvo nesse formato. Diante dessa dificuldade, escolhemos utilizar abordagens interoperáveis para implantarmos os modelos criados usando o Prophet.
Um modelo caracterizado como interoperável é aquele que pode ser desenvolvido utilizando uma determinada linguagem/sistema operacional/framework e ser executado por qualquer linguagem/sistema operacional/framework.
Normalmente, os modelos construídos usando essa abordagem são traduzidos para uma metalinguagem de acordo com uma especificação. Esse metamodelo pode ser lido por um interpretador e executado em diferentes ambientes/sistemas.
Existem várias abordagens interoperáveis na literatura e em sua grande maioria possuem dois componentes: desenvolvimento e runtime (do inglês “em tempo de execução” — figura abaixo). O componente de desenvolvimento é utilizado para converter o pipeline de machine learning para um metamodelo, enquanto o runtime é o componente capaz de ler o metamodelo e utilizá-lo em produção. O que liga os componentes e permite a interoperabilidade entre as diferentes linguagens de programação é uma especificação padrão.A seguir iremos descrever duas abordagens de modelos interoperáveis que são utilizadas no Prophet: PMML e ONNX.

O PMML (Predictive Model Markup Language) é uma abordagem baseada em XML para salvar um modelo de machine learning e é mantido pelo Data Mining Group. A versão atual é a 4.4, disponibilizada em 2019. O PMML nada mais é que um arquivo XML contendo todas as regras do pipeline do modelo. Cada algoritmo dentro do pipeline possui um parser que transforma a lógica do algoritmo para XML.A simplicidade no entendimento do código em XML para modelos pequenos é a principal vantagem do PMML, pois pode ser facilmente entendido e editável. Por outro lado, para grandes modelos, que geram PMMLs com milhares linhas de código XML, entender o fluxo pode ser uma tarefa bastante laboriosa. A principal dificuldade que encontramos nesse padrão é a complexidade na implementação de novos parsers para XML.
O Prophet utiliza o projeto JPMML como base para criar os modelos em PMML. Esse projeto contém parsers para os principais algoritmos de machine learning em Spark e sklearn. No entanto, para muito dos algoritmos do Prophet, é necessário desenvolver parsers customizados. Dependendo da complexidade do algoritmo, construir um parser para PMML pode demorar vários dias. Além disso, como o projeto JPMML é mantido por apenas um usuário, a criação de novos parsers é lenta.
Em termos de execução em produção, o PMML atende bem às
expectativas. Um modelo em PMML responde em média
por volta de 20 ms para um registro com 200 variáveis.
Outro ponto importante a se destacar é que nunca tivemos problemas de estabilidade ou disponibilidade em produção utilizando PMML.
O ONNX (Open Neural Network Exchange), assim como o PMML, permite a interoperabilidade dos componentes de desenvolvimento e runtime. Esse padrão foi criado em 2017 com o apoio da Microsoft e Facebook. Como o nome sugere, o ONNX surgiu primeiramente para suprir a necessidade de interoperabilizar os vários frameworks de redes neurais que surgiram nos últimos anos, como PyTorch, TensorFlow e Caffe. Com o passar do tempo, ele acabou abrangendo algoritmos fora do universo de redes neurais. Hoje é possível encontrar suporte para algoritmos de predição do estado da arte como XGBoost, lightGBM e CatBoost.
O ONNX funciona como um grafo, onde cada nó do grafo representa um estágio do treinamento e é chamado de operador. Dessa forma, deve existir um operador para cada algoritmo do pipeline do modelo.
A capacidade de reutilização desses operadores é sem dúvida a grande grande vantagem do ONNX. Existem operadores dos mais simples (soma, subtração, média, etc.) até os mais complexos (árvore de decisão, SVM, regressão linear, entre outros). Essa variedade nos permite criar novos operadores e combiná-los de diferentes formas. Quanto ao tempo de processamento, o ONNX responde em de aproximadamente 10 ms para um registro com 200 variáveis.
A desvantagem do ONNX está no pouco suporte às variáveis categóricas. Como o Prophet é um framework focado em dados estruturados que podem ter muitas variáveis categóricas, tivemos que desenvolver operadores para o tratamento dessas variáveis em um nível mais baixo. Dessa forma, criamos a nossa própria versão do ONNX com novos operadores categóricos nas duas pontas, desenvolvimento e runtime.
Abaixo apresentamos nossa avaliação das abordagens listadas nesse artigo. As abordagens foram avaliadas considerando o tempo de resposta, facilidade, comunidade e suporte. O tempo de resposta foi medido usando um modelo de classificação binária com algoritmos de tratamento de missing, outliers, codificação e XGBoost. A facilidade diz respeito ao quão fácil é utilizar a abordagem. A comunidade mensura o grau de atividade dos usuários da comunidade. Quanto maior e ativa for a comunidade, mais rápidas são as atualizações. Por fim, em suporte são listados os frameworks que dão suporte às abordagens.
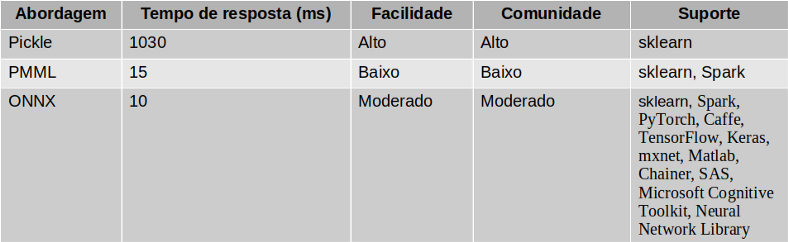
Comparação entre pickle, PMML e ONNX.Hoje na Neurotech, nosso serviço que suporta o deploy dos modelos em produção, chamado de Alfred, consegue utilizar tanto o PMML quanto ONNX de forma rápida, escalável e robusta.
Esperamos que esta breve revisão tenha sido útil aos interessados em ferramentas para disponibilizar modelos em produção. Acreditamos no poder dos dados e da inteligência artificial para abrir oportunidades e mitigar riscos com eficiência e, justamente por isso, necessitamos de modelos em produção rápidos e robustos. Se você quer entrar nesse mundo de ciência dos dados, estamos no tempo mais propício, vá em frente.
Wendeson Silva, Reniê A. Delgado e Guilherme Boaviagem Ribeiro são engenheiros de Machine Learning e cientistas de dados na Plataforma Neurolake | Neurotech


